Pandas
- Provides data analysis tools
- It can connect to and interact with a database
- It can also read and write Excel Files
Pandas Module
After importing the pandas module,
To read the excel file:
import pandas as pd
df = pd.read_excel(‘my_file.xlsx’)To read multiple sheets in excel file:
import pandas as pd
Xlf = pd.ExcelFile(‘my_file.xlsx’)
Df= Xlf.parse(‘my_sheet’)Operations
Pandas Operations
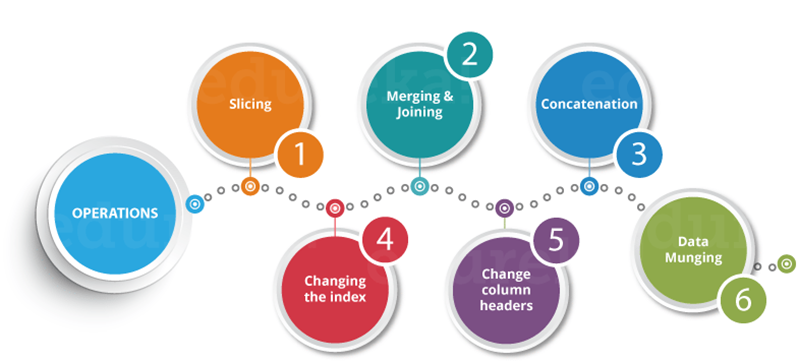
Slicing
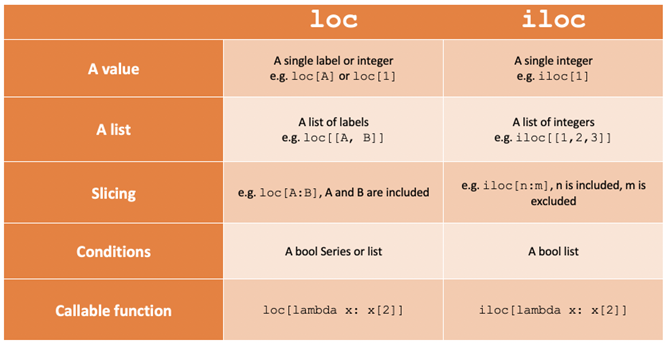
- loc gets DataFrame rows & columns by labels/names
- For loc[], if the label is not present it gives a key error.
- iloc[] gets by integer Index/position.
- For iloc[], if the position is not present it gives an index error.
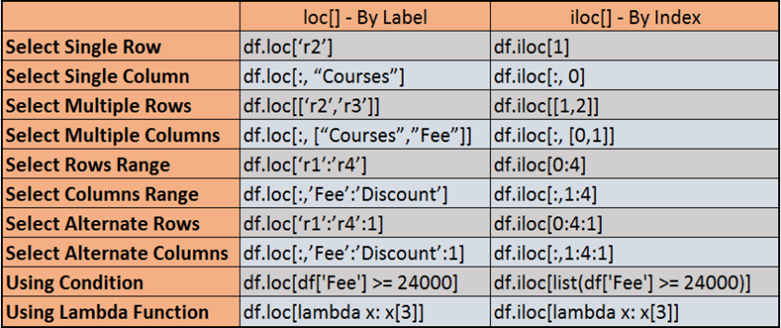
- DataFrame.loc[ ] is label-based to select rows and / or columns in pandas
- It accepts single labels, multiple labels from the list, indexes by a range ( between two indexes labels)

- START is the name of the row / column label
- STOP is the name of the last row / column label
- STEP as the number of indices to advance after each extraction
- If start row/ column is not provided, loc[] selects from the beginning
- By not providing stop, loc[] selects all rows / columns from the start label
- Providing both start and stop, selects all rows/columns in between
DataFrame.iloc[ ] is a index-based to select rows and / or columns. It accepts a single index, multiple indexes from the list, indexes by a range

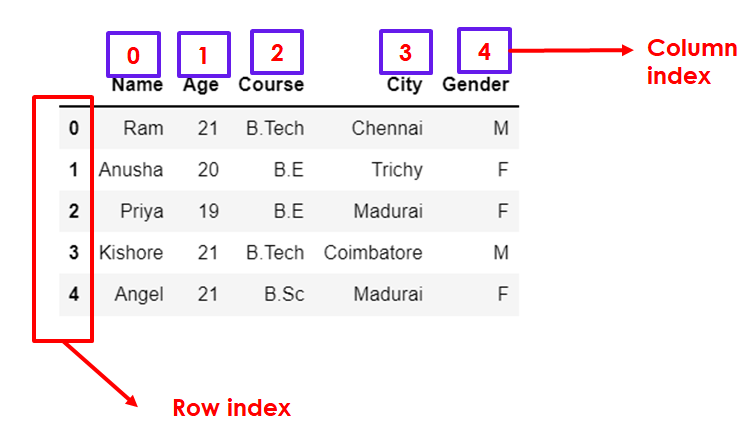
Selecting a single row
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0]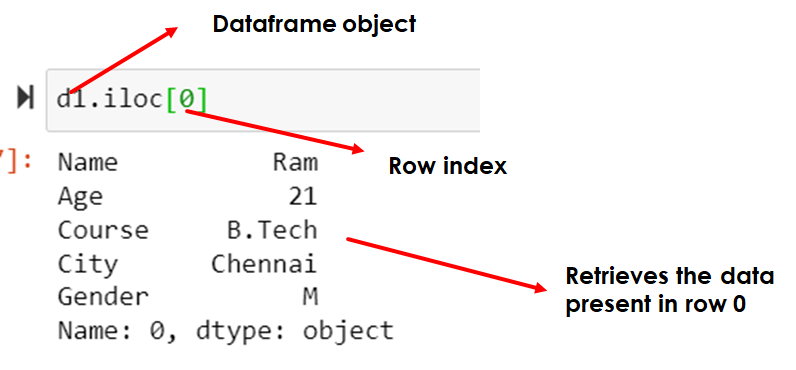
Selecting a single row: (Alternate Way)
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0,:]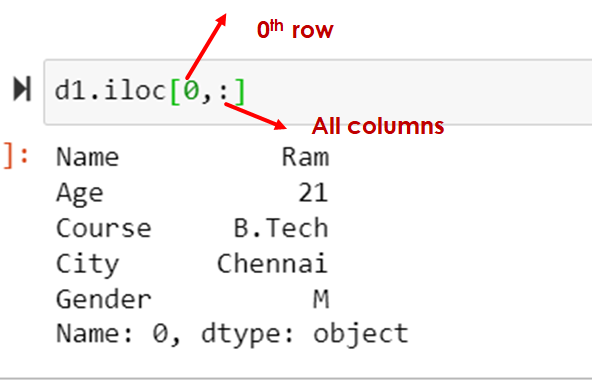
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0:1]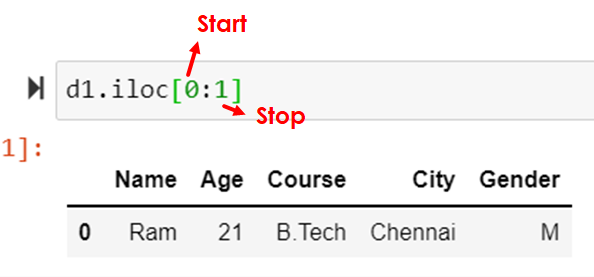
Retrieve the first column using iloc
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[:,1] # same as d1.iloc[:,1:1]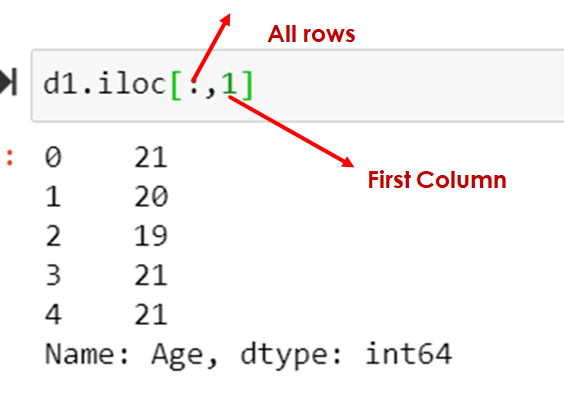
Select a single cell
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0,2]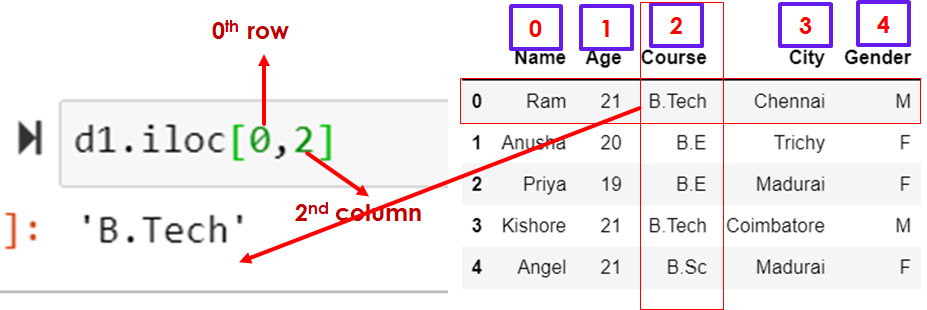
Selecting slice of rows
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0:2]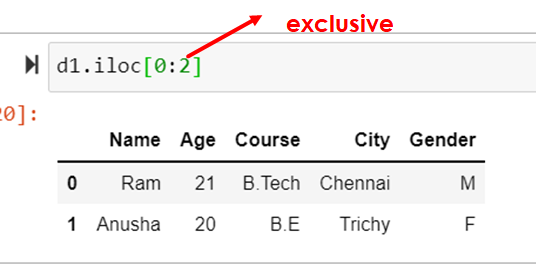
Selecting slice of columns
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[:,0:2]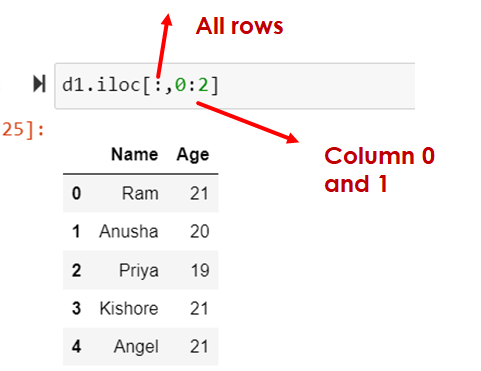
Retrieve subset of cells: retrieve rows from 0 to 3 (inclusive ) and columns till 2 (inclusive)
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[0:4,0:3]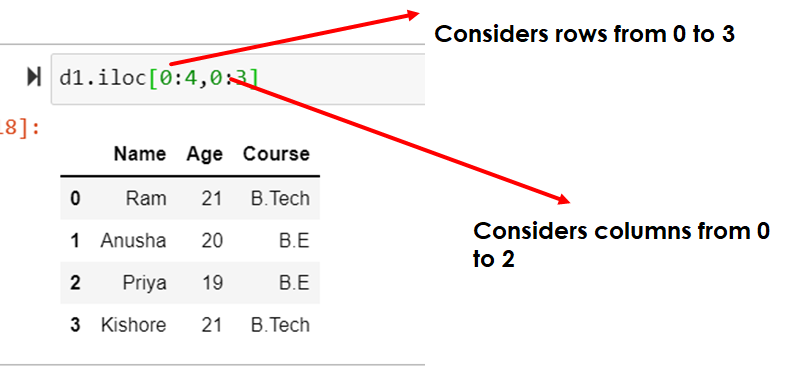
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
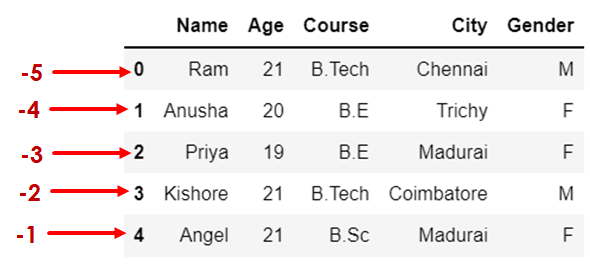
d1.iloc[-1:-3:-1,-1:-3:-1] # step size must be negative else cannot traverse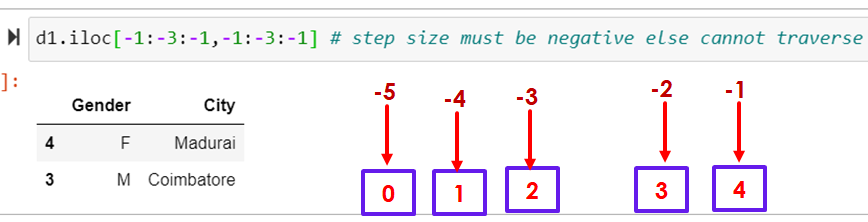
When step count is positive, proceed in right side, Else in left side
Select multiple rows
Select rows 1 and 3
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[[1,3]]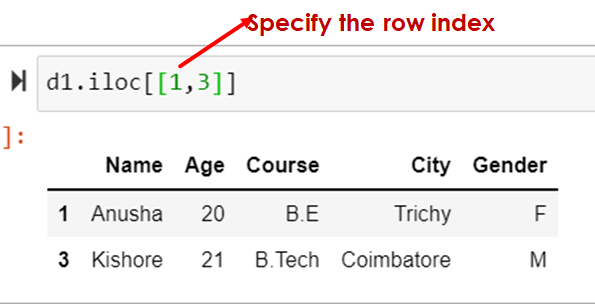
Select Multiple Columns
Example: Select the column name and course using iloc
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1.iloc[:,[0,2]]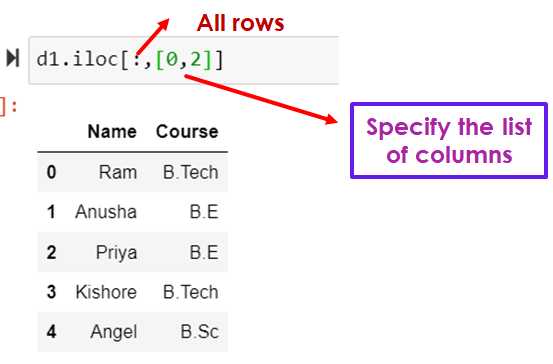
Selection based on condition
Select the students who are greater than 20
import pandas as pd
d1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Dataset5.csv")
d1
d1['Age']>20
d1[d1['Age']>20]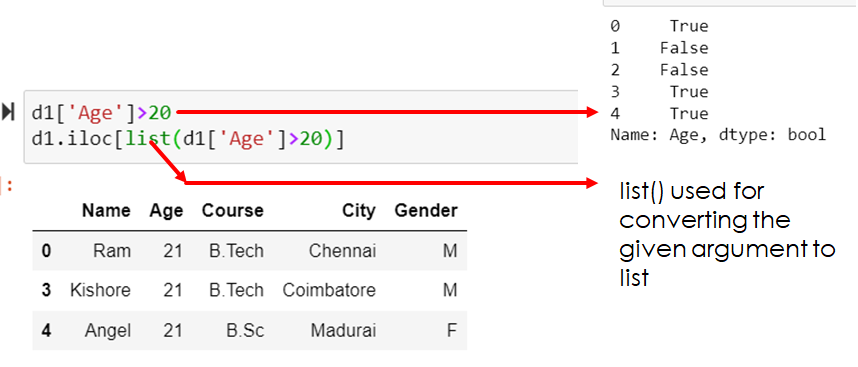
Slicing using loc
Concatenating
pd.concat() #returns a dataframeConcatenate two or more data frames into a new one
import pandas as pd
data1 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Restaurant - Week 1 Sales.csv")
data1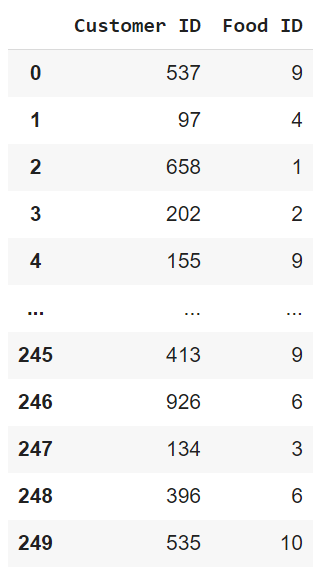
import pandas as pd
data2 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Restaurant - Week 2 Sales.csv")
data2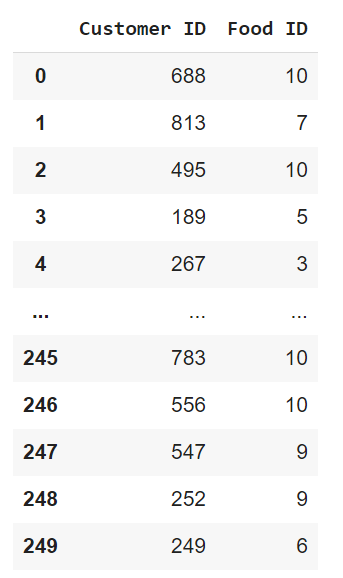
data 1 has 250 rows and data 2 has 250 rows. But the index is still to 249. because it keeps separate indexing for data1 [0..249] and data 2 [0…249
import pandas as pd
# to concatenate data1 and data2 both have same column name
pd.concat(objs=[data1,data2])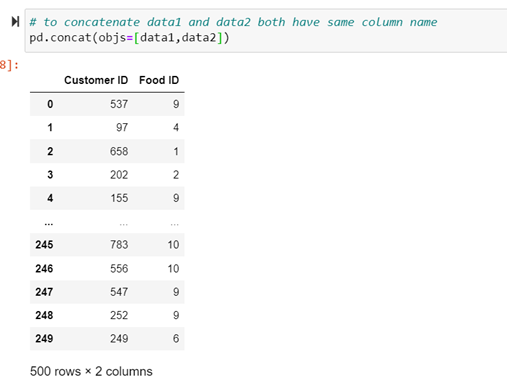
pd.concat()
By default, it is set to False. If it is set to True then, the index is continued after the instances of data1 ends
import pandas as pd
d1=pd.concat(objs=[data1,data2],ignore_index=True)
d1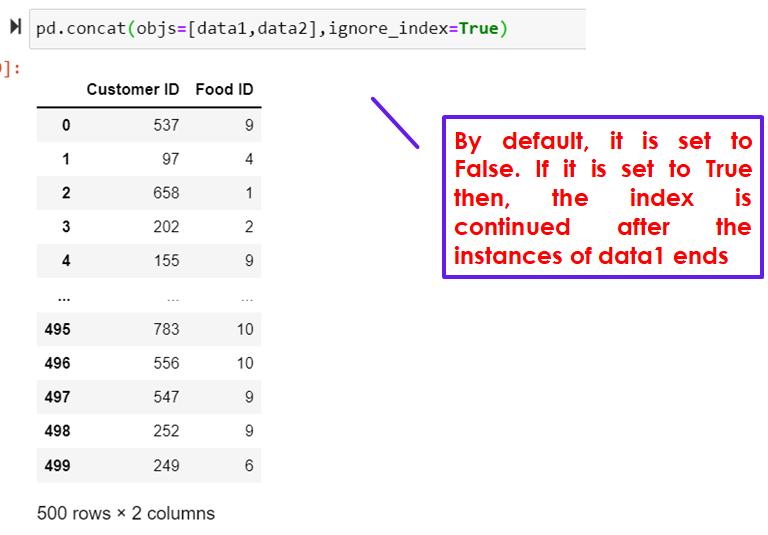
Dataframeobject.append()
import pandas as pd
data1.append(data2)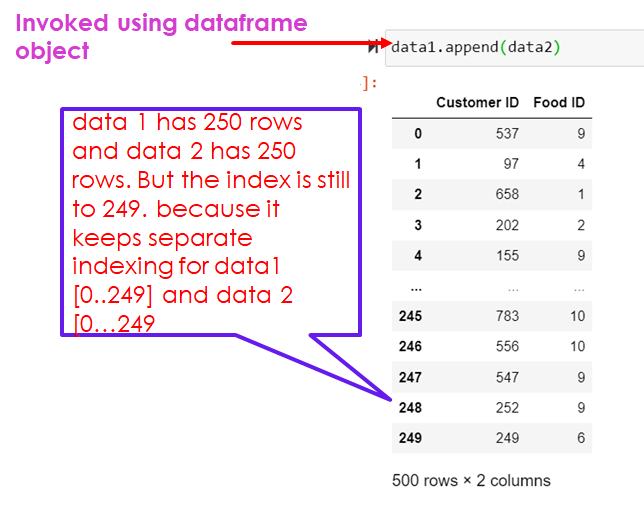
import pandas as pd
data1.append(data2,ignore_index=True)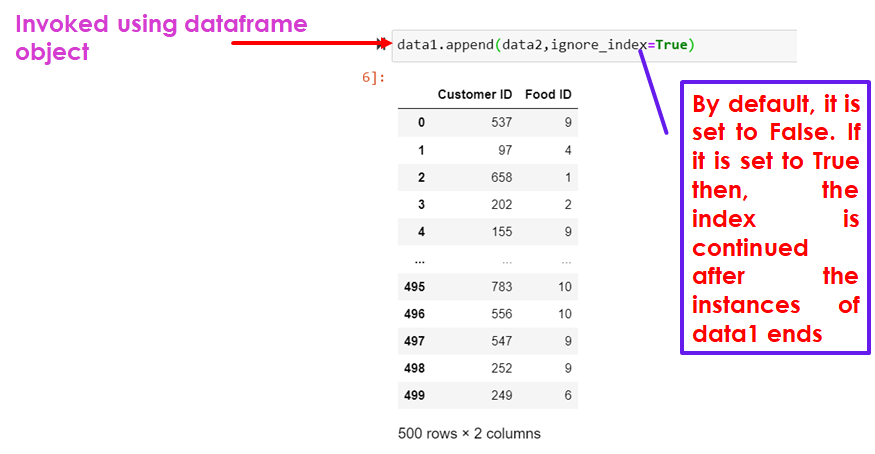
Use of the Parameter keys
import pandas as pd
vd = pd.concat(objs=[data1,data2],keys=["Week-1","Week-2"])
vd
import pandas as pd
vd = pd.concat(objs=[data1,data2],keys=["Week-1","Week-2"])
print(vd.loc[('Week-1')]) # same as vd.loc[('Week-1',)]
import pandas as pd
vd = pd.concat(objs=[data1,data2],keys=["Week-1","Week-2"])
print(vd.loc[('Week-2',)])
# to display the index of 245 belongs to Week-2
print(vd.loc[('Week-2',245)])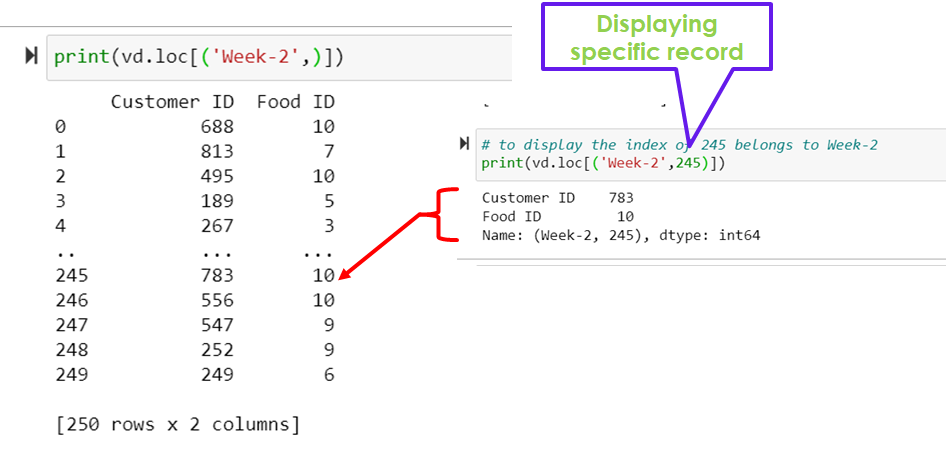
Joining
Joining two data frames when keys are in common. Based on that types of joins are given as:
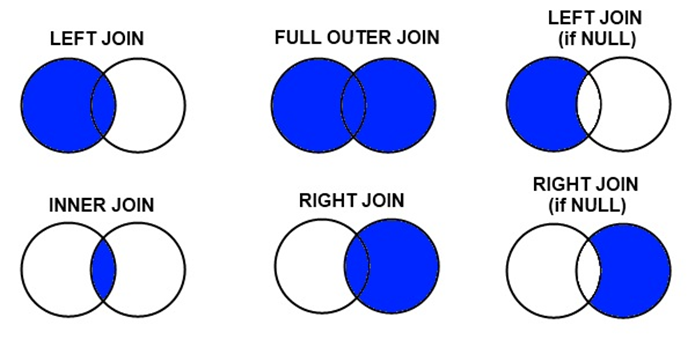
Inner Join
# Find the customers who came on both weeks
customer_both_weeks=data1.merge(data2, how="inner",on="Customer ID")
customer_both_weeks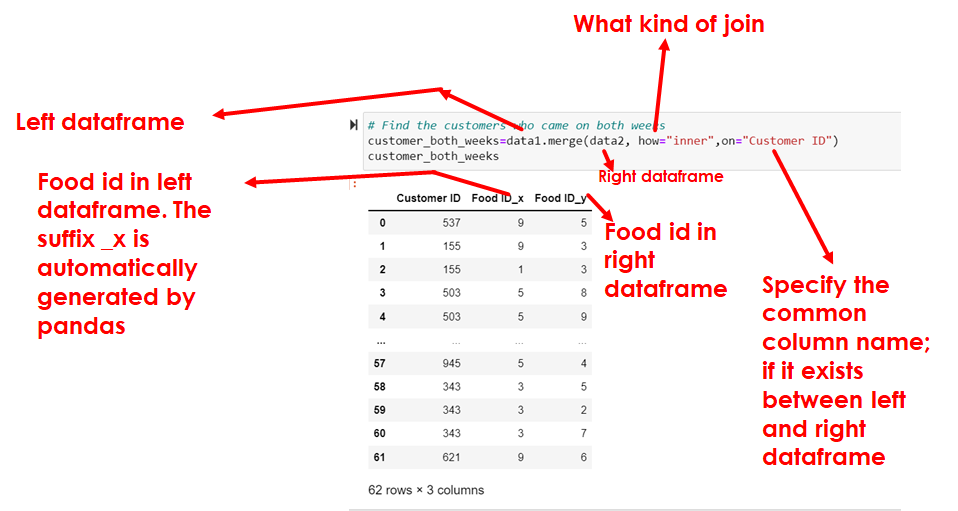
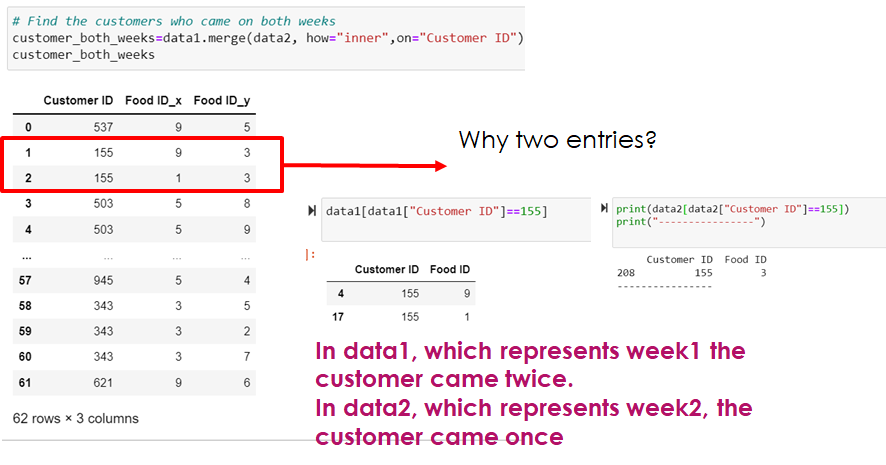
print(data1[data1["Customer ID"]==155])
print("----------------")
print(data1["Customer ID"]==155)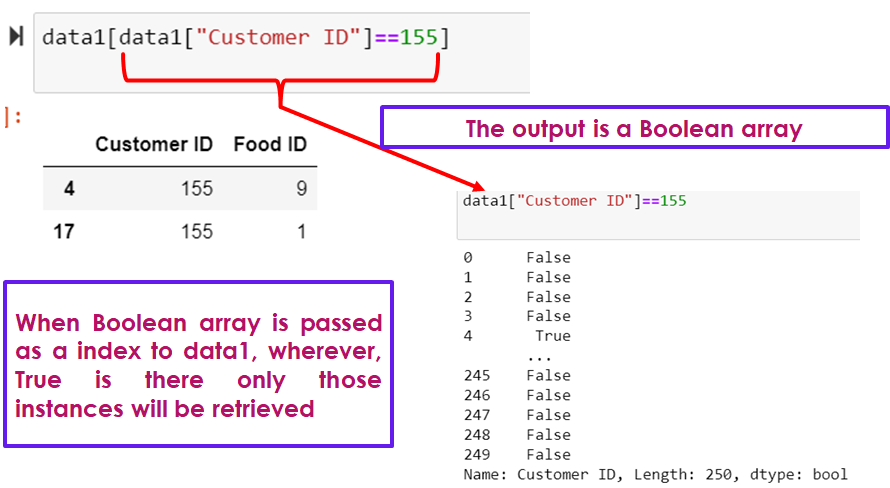
Changing the default suffixes using the parameter suffixes
customer_both_weeks_cs=data1.merge(data2, how="inner",on="Customer ID",suffixes=[":Week - 1",":Week - 2"])
customer_both_weeks_cs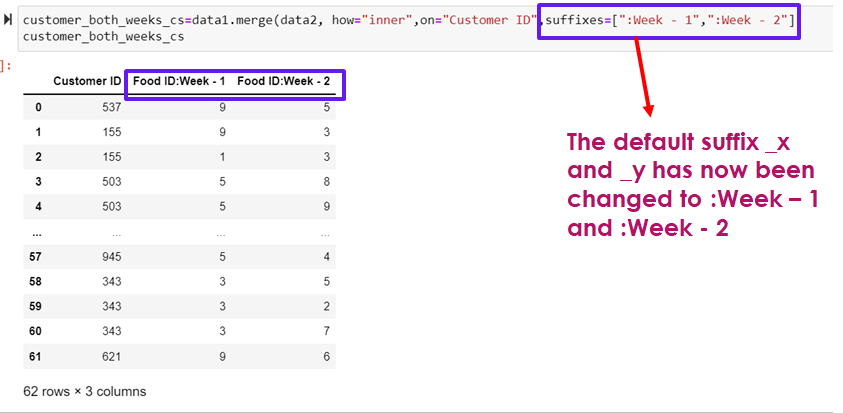
Find the Customers who came on both weeks and order same food
# Find those customers who came on both weeks and order same food
customer_both_weeks_same_food = data1.merge(data2,how="inner",on=["Customer ID", "Food ID"])
customer_both_weeks_same_food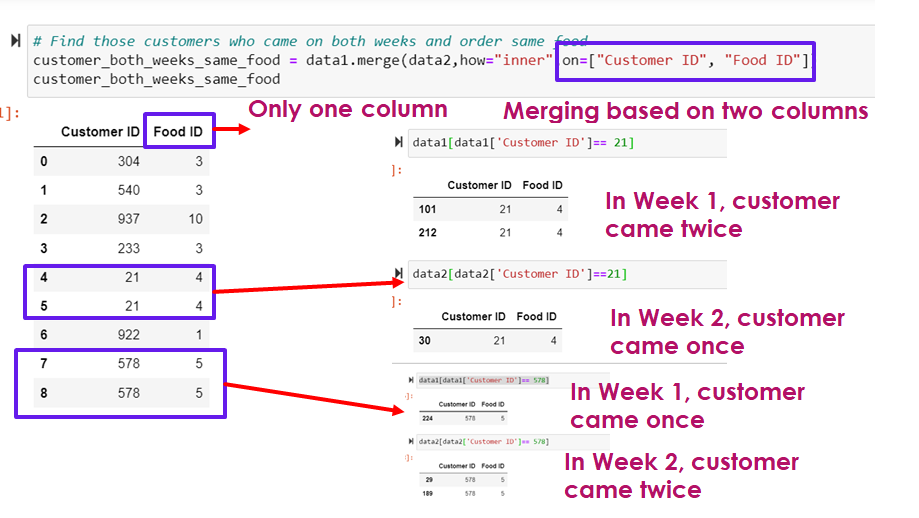
All_customers_both_weeks = data1.merge(data2,how="outer",on=["Customer ID"],suffixes=[ " - Week 1", " - Week 2"])
All_customers_both_weeks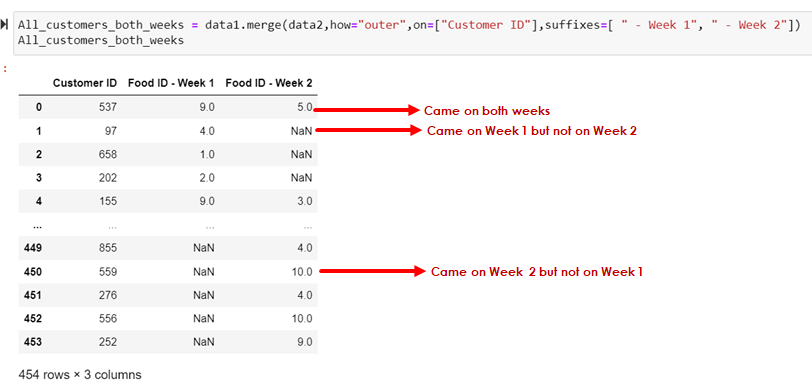
I = data1.merge(data2,how="outer",on=["Customer ID"],suffixes=[ " - Week 1", " - Week 2"],indicator=True)
I
Outer Join
print(I["_merge"].value_counts())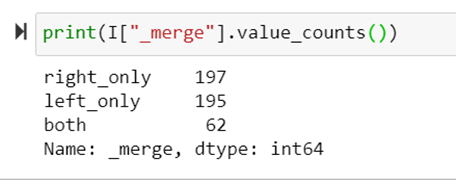
Displaying the instances either in left dataframe or in right data frame and not in both
masker = I['_merge'].isin(['left_only','right_only'])
I[masker]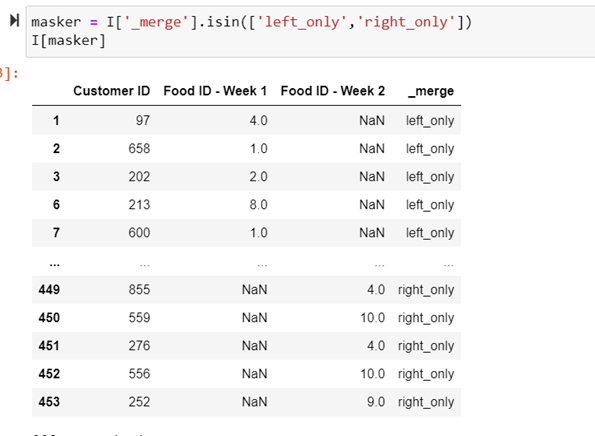
Left Join
lj = data1.merge(data4, how="left",on="Food ID")
print(lj)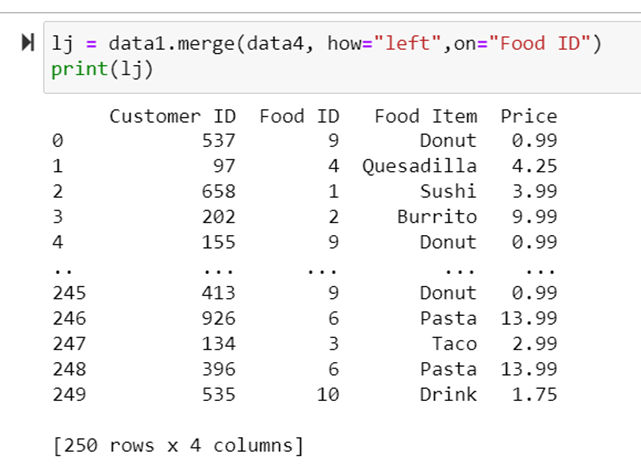
#to print the items in sorted order
lj = data1.merge(data4, how="left",on="Food ID",sort=True) #default value of sort is False
print(lj)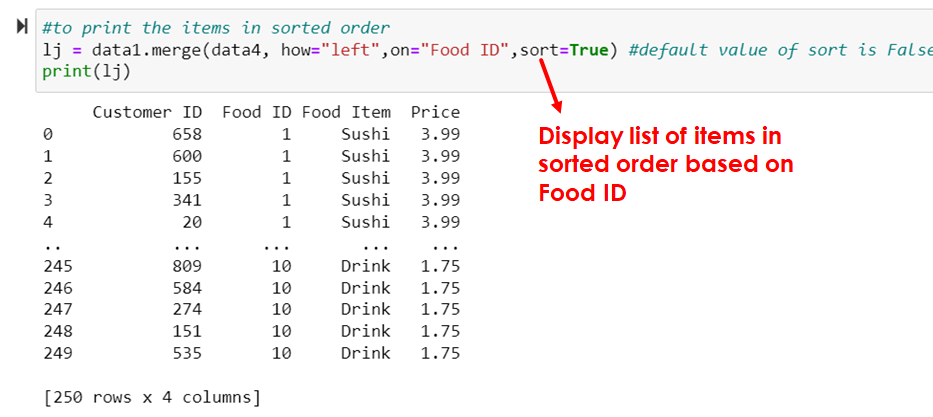
Right Join
Return all rows from the right dataframe, and any rows with matching keys from the left dataframe.
Considers instances from data4, for each matching food id in data 3, , it joins the data. Else keep the value as NaN
rj = data1.merge(data4, how="right",on="Food ID")
print(rj)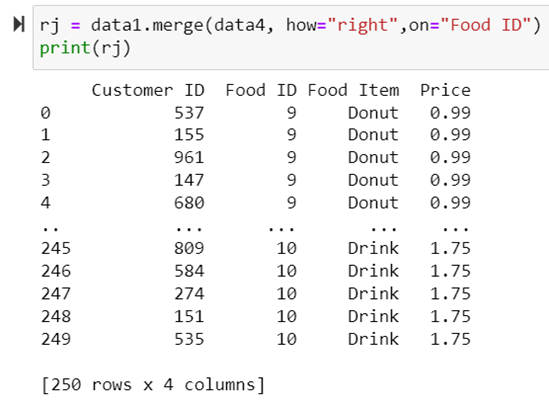
left_on and right_on parameters
- When two columns actually refer to same value but with different column names
- When the dataframes have different column names as a key then there is a need to use left_on and right_on parameter
- left_on parameter specifies: the column name that serves as a key in left data frame
- right_on parameter specifies: the column name that serves as a key in right data frame
#left_on : represents column name in left data frame
#right_on : represents column name in rigth data frame
lr = data2.merge(data3,how="left",left_on="Customer ID", right_on="ID")
lr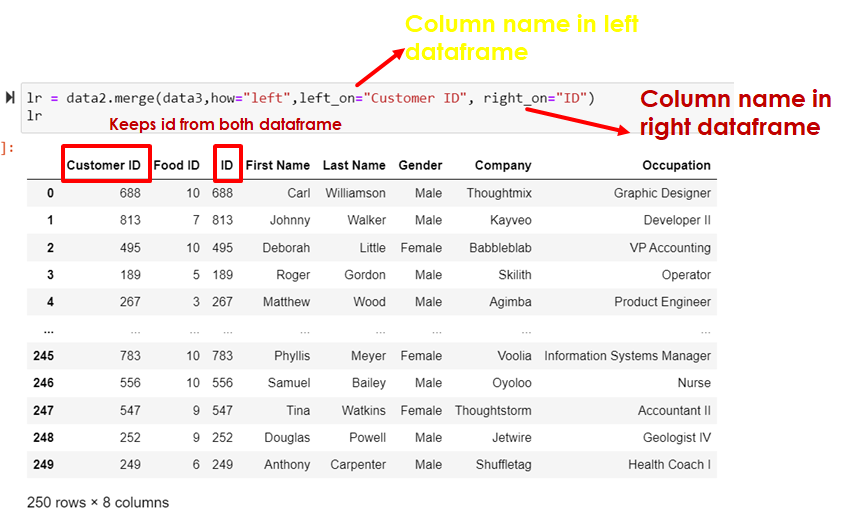
#to drop one common column use drop()
lr1 = data2.merge(data3,how="left",left_on="Customer ID", right_on="ID").drop("ID",axis='columns')
lr1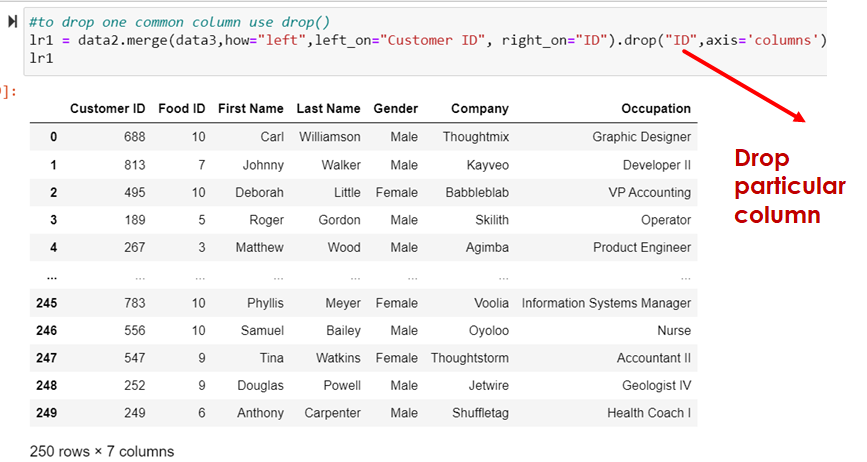
# to sort the values: user sort parameter
lr2 = data2.merge(data3,how="left",left_on="Customer ID", right_on="ID",sort=True).drop("ID",axis='columns')
lr2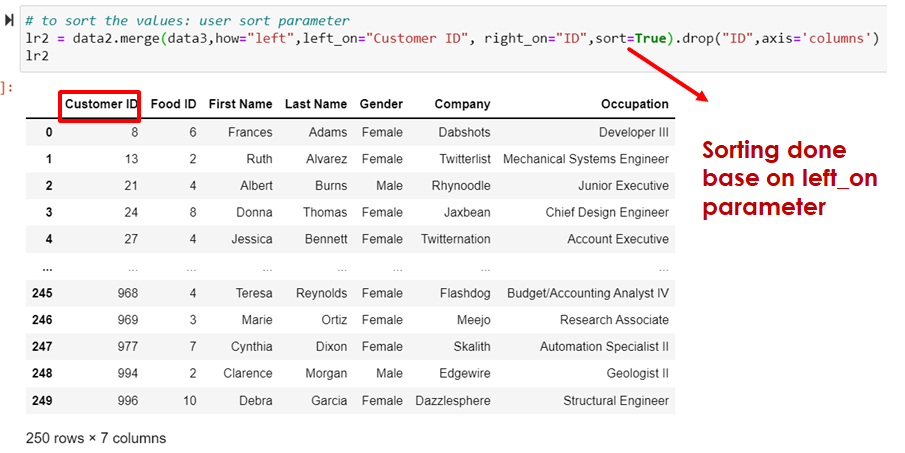
Merging by left_index and right_index parameters
data3.head(5)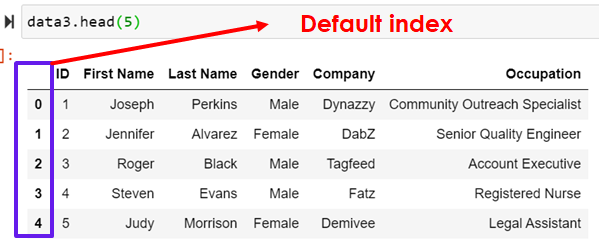
To specify the user defined index, use index_col parameter while reading the csv file in read_csv
data3 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Restaurant - Customers.csv",index_col="ID")
data3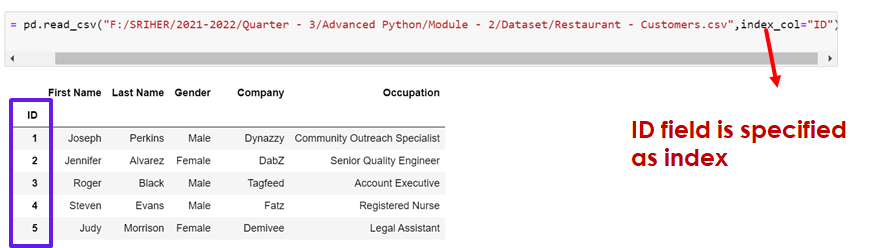
data4 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Restaurant - Foods.csv",index_col="Food ID")
data4
nd=data1.merge(data3, how="left",left_on="Customer ID",right_index=True)
nd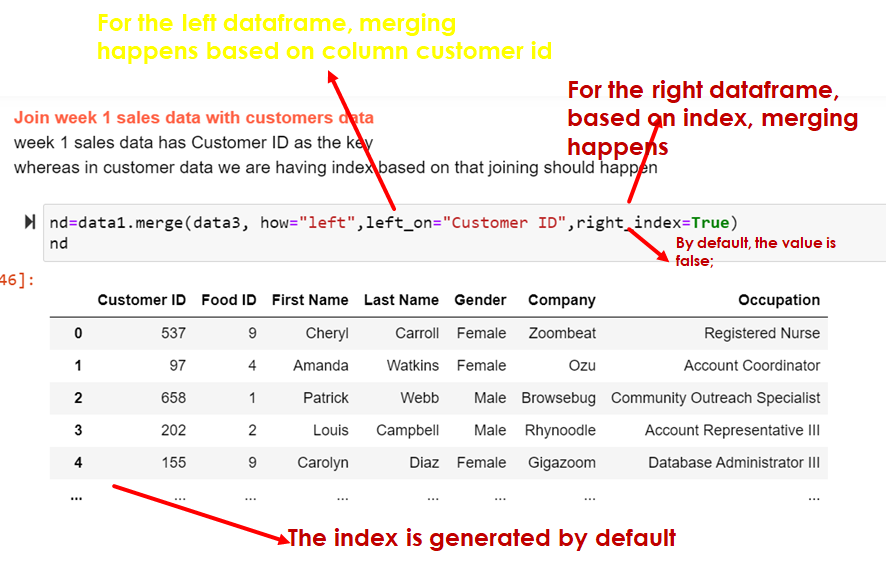
all_data=nd.merge(data4,how="left",left_on="Food ID",right_index=True)
all_data
In the restaurant example, Find the order in the which the customers arrive on week 1 and week
Solution:
The order is represented by index. In both data frames we should consider the index and based on that merging happens
order_ = data1.merge(data2,how="left", left_index=True, right_index=True, suffixes = [ " : Week 1 ", " : Week 2"])
order_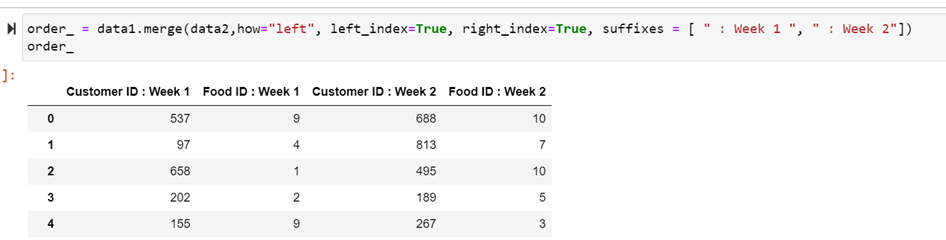
Merging: Summary
- Two columns with same name: use on
- Two columns with different name: use left_on, right_on
- Merging column with index : left_on, right_index (vice versa)
- Merging index with index: (left_index, right_index)
Joining: .join() method
When two data frames has to be joined vertically based on the index
data5 = pd.read_csv("F:/Advanced Python/Module - 2/Dataset/Restaurant - Week 1 Satisfaction.csv")
data5
sat = data1.merge(data5, how="left", left_index=True,right_index=True)
sat.head(5)
sat1 = data1.join(data5)
sat1.head(5)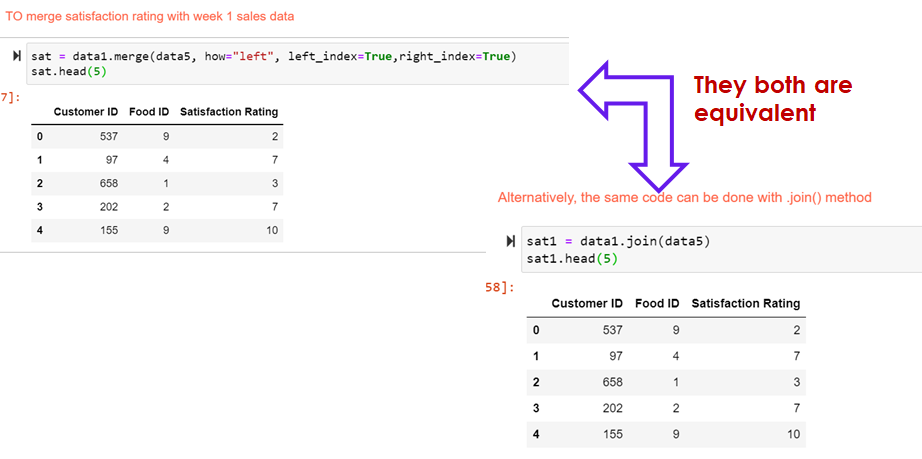
Join two dataframes vertically, when two dataframes share exactly same index
Merging: pd.merge() method
- So far, merge method has been called on pandas object
- merge() method can be invoked on pandas library as pd.merge()
cus_info = pd.merge(data1,data3,how="left",left_on="Customer ID", right_on="ID")
cus_info.head(3)
cus_info1=data1.merge(data3,how="left",left_on="Customer ID", right_on="ID")
cus_info1.head(3)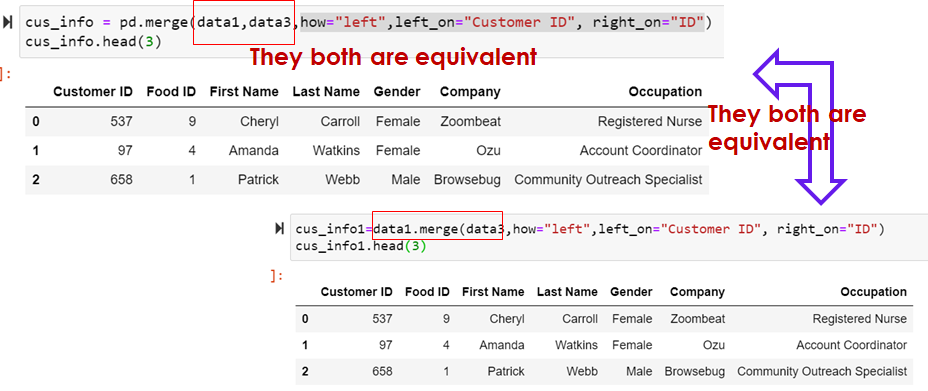
Views: 5