Table of Contents
show
Standardization (Z- Score Normalization)
A variable is made to follow standard normal distribution.
Aim: The features will be rescaled to ensure the mean and standard deviation to be 0 and 1, respectively
Formula
\[x_{new} = {x_{old} – \mu\over \sigma}\]
Where,
\[\mu\]
\[\]
\[\sigma\]
represents Mean
represents Standard Deviation
Why Data Standardization?
- It is very necessary for the data to have the same scale in terms of the Feature to avoid bias in the outcome
- Ex: A variable X has a range of 0 – 1000 and variable Y has a range of 0 – 10.
- Variable X will outweigh variable Y due to it’s higher range
sklearn
- Most useful library in python for machine learning
sklearn.preprocessing
- Package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for processing
StandardScaler
- Standardize features by removing the mean and scaling to unit variance
- This operation is performed feature-wise in an independent way
fit_transform
- Fit to data, then transform it
- The fit method is calculating the mean and variance of each of the features present in our data
- The transform method is transforming all the features using respective mean and variance
- Once the mean and standard deviation of the Feature F at a time is found, it will transform the data points of the Feature F immediately
import pandas as pd
from sklearn import preprocessing
df_zs1 = pd.read_csv("F:/SRIHER/2021-2022/Quarter - 3/Advacned Python/Module - 1/Dataset/D9.csv")
#creating object
sca = preprocessing.StandardScaler()
#Invoking fit_transform() using object created for StandardScaler
df_zs1_after_standardization = sca.fit_transform(df_zs1)
print("After Data Standardization")
df_zs1_after_standardization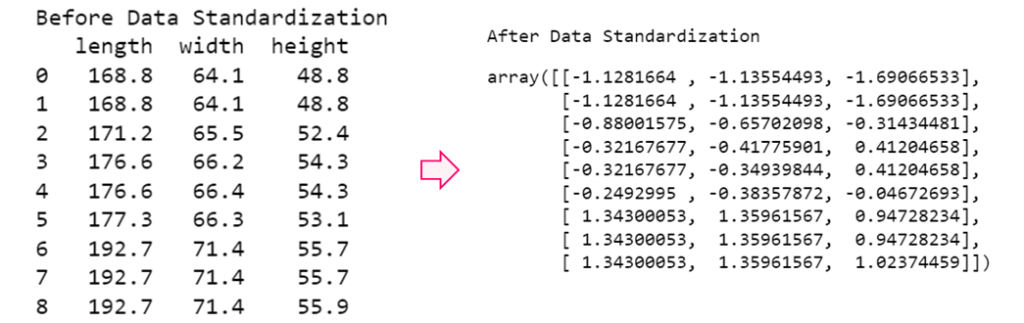
Views: 1